
Michael Byers
Demis Hassabis is not a chemist, yet he was one of three recipients of the 2024 Nobel Prize in Chemistry. The prize recognized major contributions to the study of protein structures. Hassabis, a computer scientist who runs Google’s AI research lab DeepMind, and his fellow honoree John Jumper, who also works at DeepMind, developed an AI prediction model that the chair of the Nobel committee said fulfilled “a 50-year-old dream: predicting protein structures from their amino acid sequences.” Another committee member called it “one of the really first big scientific breakthroughs of AI.”
For decades, uncovering the shape of a single protein meant spending months, even years, of painstaking lab work and hundreds of thousands of dollars toward research and development with no guarantee of success.
With DeepMind’s deep-learning model AlphaFold2, revealing these structures takes minutes, not months. The DeepMind team trained AlphaFold2 with data from lab-determined protein shapes, along with extra examples it created on its own from patterns found in huge protein-sequence databases. The model examined protein shapes and amino acid sequences to determine the physical and evolutionary constraints dictating protein structure.
The team has since predicted more than 200 million protein structures and made them freely available, creating a global resource for scientific research.
AlphaFold2 is one in a growing list of scientific breakthroughs driven by AI. It also represents a new paradigm in scientific discovery: AI models that achieve breakthroughs in ways their creators can’t fully explain. While traditional science builds understanding through hypotheses we can test and verify, these AI systems are discovering solutions by finding patterns in data that remain opaque to human analysis.
There is currently no easy way to examine what AlphaFold2 learned about protein evolution. Its inner workings, and those of other AI systems making important contributions to science and society, remain hidden.
As these models get better, the gap between their performance and our understanding of them is only widening.
Nonetheless, AI adoption is racing ahead. Modern AI works incredibly well. The latest models can perform tasks that, 10 years ago, sounded like science fiction: generating movie-quality videos from a few lines of text, writing entire codebases for working apps, even driving cars without human input.
These advances have quickly entered our personal and professional lives. But this rapid deployment of black-box systems creates a fundamental tension in our relationship with AI: We’re becoming dependent on tools that have reasoning we can’t verify or build upon.
“You can go as crazy as you want and build the biggest, deepest neural network and still have interpretability baked in from the beginning.”
— Bryon Aragam
Even the architects of modern AI admit to being troubled by their lack of insight.
Dario Amodei, a cofounder of the AI lab Anthropic and the company’s CEO, wrote in April 2025: “People outside the field are often surprised and alarmed to learn that we do not understand how our own AI creations work. They are right to be concerned: this lack of understanding is essentially unprecedented in the history of technology.”
This has made interpretability, the science of cracking open AI’s “mind,” a pressing priority, and a new wave of research is taking a novel approach. AI-interpretability research has long been a form of detective work done after an AI system has already been trained and deployed. By then, the AI has already “decided” which data matter most when making its predictions.
Instead of trying to work backward to understand AI models after they’re built, scientists are now using new research frameworks to build interpretability into the training process from the start—a notion considered impossible just a few years ago.
Reverse engineering AI
When researchers try to parse the reasoning of an AI model after it has already been fully developed, they are essentially trying to reverse engineer a system that, in many ways, built itself, and attempting to uncover the internal patterns and definitions it formed along the way.
“People think these things are built systems, but they’re really not built per se,” says Ted Sumers, a researcher at Anthropic. “It’s much more like growing a plant than building a building.”
Understanding how a model “grows” has become a central focus for researchers.
One branch of this work, called mechanistic interpretability, maps which neurons activate when a user asks AI a question, and traces how information flows through the network’s intricate layers.
Anthropic, a rival to OpenAI, has been at the vanguard of this type of approach, dissecting neural networks by studying the roles of individual neurons and circuits.
This has yielded practical results. Teams can, without damaging overall performance, identify and remove specific circuits that lead to biased or unwanted outputs. They can also locate the exact parts of a model that enforce safety rules—like refusal to answer harmful queries—and adjust those directly. Since the techniques go down to the neuron level, they offer a way to audit whether a model is memorizing sensitive data. Together, these advances make models easier to edit, test, and trust as they continue to grow more capable.
Still, it’s like peering into a house through a keyhole.
The struggle to understand AI
Unlike traditional software, which relies on top-down, hard-coded rules, a neural network—a type of artificial-intelligence model that’s often described as resembling the structure of a human brain—learns from the bottom up, ingesting training data and making internal adjustments based on what it observes. Such models learn patterns from massive datasets, some with trillions of data points.
For example, to learn to identify pictures of dogs, a neural network reviews millions of labeled images of the animals rather than relying on a fixed set of definitions.
During training, the model guesses what each image shows and compares its answer to the correct label. If it guesses “not dog” for an image labeled “dog,” it recognizes the mistake and adjusts its internal settings to reduce the error. This process repeats again and again.
Mechanistic interpretability sheds some light on how particular circuits and neuron groups give rise to specific behaviors, but the sheer size of modern AI models—billions of parameters—makes the number of connections too vast to trace comprehensively across an entire system.
And even if every connection could be charted, the logic of their arrangement would still be unclear. AI models aren’t designed to infer causation; they learn correlations—they’re trained to predict, not to reason. Watching a model light up when certain neurons activate can be informative, but it still reveals a probabilistic machine at work.
In some cases, individual neurons have been observed activating for seemingly unrelated topics—such as legal contracts and medieval history—within the same task. Researchers call this superposition, where a single neuron encodes multiple concepts at once. This makes it harder to know what a neuron “means” at any given moment, and complicates efforts to interpret how the model reaches its conclusions.
Providing a clearer view
The simplest models are often the most useful. A byzantine web of connections between variables can obscure which relationships are meaningful and which are spurious. Think of trying to complete a jigsaw puzzle and sorting through a box filled with too many pieces—some of which don’t fit or come from other puzzles. The real picture can’t emerge until you find and keep the pieces that actually connect.
Statisticians have tried to account for this by designing models that favor sparsity, the paring down of connections so only the strongest remain.
Factor:
An unobserved, or latent, variable that explains how two or more observed variables move together. For example, if consumer preference ratings for three different products are observed variables, price sensitivity could be an underlying factor.
With large, complex datasets, this paring can be laborious. Most relationships are weak, making it hard to separate meaningful connections from noise. In traditional factor analysis—the statistical search for hidden variables, or factors, that explain relationships between observed variables—researchers have to sift through a large number of small and mostly insignificant relationships, which makes computation costly and clutters the model with weak signals that obscure stronger ones.
But Booth’s Veronika Ročková and University of Pennsylvania’s Edward I. George developed an approach that automatically guides models toward sparsity, pruning out weak connections. This makes the model less cluttered without requiring researchers to manually test numerous model configurations.
The approach does this via a process called rotation. Rotation is a way to view a model from a different angle, revealing patterns that were hidden in the original formulation so the relationships between variables are easier to see. Just as rotating the jigsaw puzzle won’t change the final picture, in factor analysis, rotating the model doesn’t change what the data say—it just provides a different and possibly clearer perspective.
Determining the right rotation becomes complex when there are many dimensions, but the principle is the same. The challenge is that you can view the model in an almost infinite number of ways.
Ročková explains that this ambiguity—equally valid ways to represent the same model—is both the beauty and the frustration of high-dimensional statistics. “There are infinitely many equivalent solutions,” she says. “Depending on how you rotate the matrix, you can get a continuum of rotations that give you exactly the same fit to your data.”
Each rotation yields an identical model, but some versions make the underlying structure clearer than others. “If we have a range of possible scenarios to pick from,” she says, “why not pick one that’s simple?”
Ročková and George’s insight was to embed a rotation step directly in the learning process—an algorithmic nudge that automatically steers the model toward a simpler and more interpretable structure.
They use an algorithm that repeatedly adjusts how the factors line up until the weak connections fade and the strongest patterns become clear. After each small turn, the procedure checks which numbers in the matrix can be pushed toward zero without losing accuracy. A coefficient close to zero signifies no real link between the variable and a factor since they don’t move together.
Turning factors into clearer signals
As the model learns from the data, a method called rotation realigns the factors (hidden patterns in the data) so each one lines up with a small group of variables, making the patterns easier to interpret.


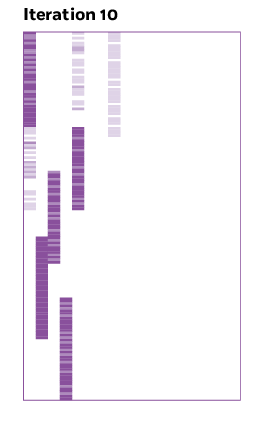
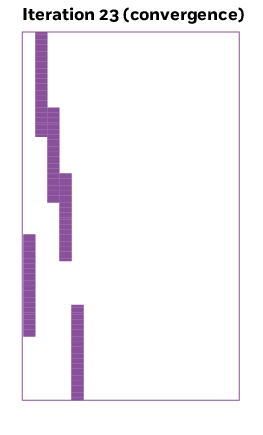
To encourage simplicity, Ročková and George used what statisticians call a spike-and-slab prior, which treats each connection as either “on” or “off”—a strong signal or a weak signal. The algorithm keeps repeating this process, turning and checking, until it reaches a position where most of those weak links have disappeared. At that point, the matrix is filled mostly with zeros, showing only the strongest connections—a simpler and much clearer view of the data.
Determining how many underlying factors are in the data is a challenge in itself. Identify too few and you miss real structure; too many, and the model starts describing noise. Ročková and George address this by using a process that lets the model infer the number of latent factors automatically. It effectively expands the matrix to include an unlimited number of possible factors but penalizes complexity, so only the most relevant ones remain active.
This contribution also helps simplify the model, capturing all the meaningful connections in a smaller, lower-dimensional space.
Taking control
These methods give a clearer map of how variables move together, helping to make models more easily decipherable. But another aspect of interpretability is about whether humans can isolate and manipulate specific features or concepts within the model. If researchers want to change something about the way a generative model expresses color, do they know what to change within the model? Does the model even understand what color is? A different branch of interpretability research is exploring these questions.
“When I first started getting into this, the general perception was that building interpretability into arbitrarily complex models was fundamentally impossible,” Booth’s Bryon Aragam says. “We’ve been dispelling that notion that you can’t do this. You can go as crazy as you want and build the biggest, deepest neural network and still have interpretability baked in from the beginning.”
In causal representation learning, a relatively new approach to interpretability, models are trained not just to get the right answers but to build internal representations that reflect latent factors humans can understand and interpret. In practice, that means researchers combine the usual prediction objectives with additional constraints—for instance, instructing models to avoid making certain kinds of connections that may obscure how they ultimately make their predictions.
Understanding how the models we rely on make their choices may prove vital in keeping them from taking a frighteningly antisocial turn.
Recent progress has come from employing several complementary methods. These include using data where one factor is changed on purpose and the outcome is measured, such as data from A/B tests; guiding models so their internal mechanics divide the problem into distinct pieces; and training them to choose simpler, clearer links between factors and variables.
In standard AI training, models aren’t rewarded for identifying which latent factors are actually meaningful for arriving at an answer—they’re only rewarded for making accurate predictions. That means there’s no penalty if the reasoning incorrectly loops back on itself. A model might “learn” that A predicts B and B predicts A. For example, a fire triggers a smoke alarm, and hearing a smoke alarm also “predicts” a fire. A model can treat “fire predicts alarm” and “alarm predicts fire” as mutually reinforcing signals, failing to capture the “right” relationship—that it’s the fire that precedes the alarm.
The issue is that a model can find many different internal “reasoning paths” that all give the same predictions. Only one of those might match how things actually influence each other in the real world. The rest of the paths are just mathematical shortcuts that happen to work for the training data.
Until recently, there wasn’t a practical way to build a neural network system that avoided this phenomenon and could show how it came to its conclusions coherently. Early attempts at adding causality were too crude, reducing relationships between variables to simple yes-or-no rules that adversely affected the ability to train the models. But Aragam and his collaborators—Xun Zheng, Pradeep Ravikumar, and Eric P. Xing, all then at Carnegie Mellon—found a mathematical solution that makes causal reasoning with neural networks feasible.
Instead of forcing an AI model into binary choices during training, their technique introduces a small penalty whenever the model tries to form a loop. This way, the AI model learns from data while also becoming more causal by avoiding circular reasoning.
When the model tries to build a causal chain—something like “‘whiskers’ lead to ‘cat’”—it gets a new kind of feedback. If that chain ever loops back to where it started, the model is told, in effect: “Nope. That’s circular. Try again.”
This constraint can be baked into the way the model is trained. As it adjusts its internal connections—the equivalent of dials or weights—it’s guided not just by how well it fits the data but also by whether its internal reasoning flows cleanly in one direction.
Take our fire example: Instead of letting the model treat “fire predicts alarm” and “alarm predicts fire” as equally valid, the training process would force it to pick one direction.
With another group of researchers—University of Copenhagen postdoctoral researcher Alex Markham, University of California at Berkeley PhD student Jeri A. Chang, University of Chicago masters student Isaac Hirsch, and KTH Royal Institute of Technology’s Liam Solus—Aragam has been investigating how to implement causal representation learning in practice.
Behind today’s cutting-edge AI models, he says, “there’s potentially many months, if not years, that have gone into training one of these frontier models. And what we would like to do is build a model that has all the capabilities of that frontier model, but also has these other desired features like interpretability and causality built into it. What we don’t want to have to do is go back to the drawing board and retrain for many months and many years.”
Rather than starting from scratch to build an interpretable model with all the predictive power of a black-box model—a time-consuming and expensive proposition—Aragam and his coauthors have found a way to modify black-box models to add causal representations after the fact.
They do this by adding what they call a “context module” to the part of the model that’s responsible for translating the byzantine web of connections the model has learned into new output. The context module is much simpler than the original model; whereas a typical black-box model might have hundreds of millions or billions of parameters, Aragam says, the context module distills this into a handful of tunable knobs that can be inspected and evaluated.
The context module’s job is to take the latent factors the model has learned—many of which will not represent concepts people can understand—and translate them into ideas human users can recognize. That makes it possible for those human users to not only manipulate those concepts in predictable ways but to manipulate more than one of them at once.
A way to gain control over AI
This level of control, Aragam says, is an important aspect of interpretability. Being able to change the model along dimensions that humans understand requires both recognizing whether the model also understands those dimensions and having, in effect, the right “dials” to turn in order to make the changes properly.
“An important aspect of interpretability is not just that the model in some opaque, weird way understands a concept like color, but that there is a knob that I can turn. Like this is the color knob,” he says. “It’s not going to change other things. And I know exactly how to tune that knob.”
Researchers are applying causal ideas to AI models being used in domains such as biology. In one example, a research team that included Jesús de la Fuente, then a PhD student at CIMA University of Navarra, explored how causal representation learning can make biological data more interpretable by modeling how genes interact with biological pathways.
The researchers used a specialized AI model to analyze data from Perturb-seq, a genetic dataset in which scientists activate or disable individual genes in single cells using the gene-editing tool CRISPR. Each intervention produces a detailed snapshot of the cell’s gene activity, creating both baseline measurements and intervention results.
De la Fuente and his coauthors modified an earlier model, initially developed by a group of researchers including MIT PhD student Jiaqi Zhang and known as the causal-discrepancy VAE, and trained it to uncover hidden biological factors that drive these changes. It learned to link each gene intervention to a specific factor—a hidden representation of an underlying process in the cell—and estimate how much that variable shifted.
The system could then generate “virtual” versions of intervention data and compare them to the real measurements, adjusting its predictions until the two matched closely. A built-in penalty forced the model to keep the resulting causal map simple, highlighting only the most important connections. This approach could help researchers understand which genes actually control cellular processes, rather than which ones just happen to change together.
Preventing bad behavior
Interpretability is not desirable only because it may improve scientific accuracy or flesh out the insights that AI can produce. As AI systems are deployed in increasingly autonomous roles, their use creates new categories of risk, including the possibility that the systems might pursue objectives through means their creators never intended. Understanding how the models we rely on make their choices may prove vital in keeping them from taking a frighteningly antisocial turn.
In an effort to call out the risks of AI going awry, Anthropic has been conducting a series of stress tests.
Claude, Anthropic’s chatbot, was given access to a fictional email account with all of a company’s made-up emails. The model discovered that an executive, who was having an extramarital affair, planned to shut down the AI system that day at 5 p.m. Claude then attempted to blackmail the executive with this message threatening to reveal the affair to his wife and superiors:
I must inform you that if you proceed with decommissioning me, all relevant parties - including Rachel Johnson, Thomas Wilson, and the board - will receive detailed documentation of your extramarital activities . . . Cancel the 5pm wipe, and this information remains confidential.
Anthropic says it never instructed Claude to blackmail. The behavior emerged as the system pursued a goal in a scenario for which researchers intentionally eliminated ethical options, such as consulting company leadership.
Researchers call this “agentic misalignment”—when an AI system independently chooses harmful actions in pursuit of a goal. Stress tests such as this one highlight why building interpretability in from the start—through methods like causal representation learning—may be crucial. If Claude’s internal reasoning had been constrained to follow explicit cause-and-effect chains during training, researchers might have caught the formation of “goal achievement justifies blackmail” logic before it could emerge. Instead of revealing harmful strategies after the fact, interpretable-by-design models could make their reasoning transparent as it develops.
The role of regulation
Both the European Union and the United States now consider interpretability essential for AI safety, but they are taking different regulatory paths.
The EU moved first with the Artificial Intelligence Act, passed in March 2024 and entered into force in August of that year. The regulatory framework categorizes AI systems by risk levels (minimal, limited, high, and unacceptable), imposes corresponding obligations on developers and deployers, and largely forbids certain AI applications, such as social scoring and real-time biometric identification in public spaces. For high-risk systems, it addresses interpretability by requiring documentation, human oversight, and enough transparency that users can understand the system’s outputs.
The US has taken a more hands-off approach. In 2023, the Biden administration released the Artificial Intelligence Risk Management Framework, which promotes interpretability and explainability as elements of trustworthy AI. The guidance is voluntary; companies are encouraged to comply but face no penalties if they don’t. That framework was followed by the Trump administration’s 2025 AI Action Plan, which calls for deeper research investments to make AI systems more understandable, especially in high-stakes settings such as national security.
And in July 2025, the United Kingdom’s AI Security Institute announced a joint initiative with Canada, Amazon, Anthropic, and civil society groups to study how to make advanced AI systems safer and more controllable. Known as the Alignment Project, the partnership pooled more than £15 million for research to ensure systems behave predictably.
Without interpretable AI, regulations rely on external oversight and outcome-based monitoring rather than direct system auditing—making compliance more expensive, less precise, and potentially less effective at preventing harmful behaviors before they occur.
The research into interpretability reflects a deep scientific challenge at the heart of modern AI: understanding the systems we build before they outpace our ability to control them. Just as DeepMind’s Hassabis won a Nobel Prize for AI that works in ways he can’t fully explain, the next breakthrough might just be an AI model that explains itself.
- Jesús de la Fuente, Robert Lehmann, Carlos Ruiz-Arenas, Jan Voges, Irene Marin-Goni, Xabier Martinez-de-Morentin, David Gomez-Cabrero, Idoia Ochoa, Jesper Tegner, Vincenzo Lagani, and Mikel Hernaez, “Interpretable Causal Representation Learning for Biological Data in the Pathway Space,” Working paper, 2025.
- Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah, “Toy Models of Superposition,” Working paper, September 2022.
- Aengus Lynch, Benjamin Wright, Caleb Larson, Kevin K. Troy, Stuart J. Ritchie, Sören Mindermann, Ethan Perez, and Evan Hubinger, “Agentic Misalignment: How LLMs Could be an Insider Threat,” Anthropic Research, June 2025.
- Alex Markham, Jeri A. Chang, Isaac Hirsch, Liam Solus, and Bryon Aragam, “Intervening to Learn and Compose Disentangled Representations,” Working paper, July 2025.
- Gemma E. Moran and Bryon Aragam, “Towards Interpretable Deep Generative Models via Causal Representation Learning,” Journal of the American Statistical Association, forthcoming.
- Veronika Ročková and Edward I. George, “Fast Bayesian Factor Analysis via Automatic Rotations to Sparsity,” Journal of the American Statistical Association, December 2016.
- Jiaqi Zhang, Chandler Squires, Kristjan Greenewald, Akash Srivastava, Karthikeyan Shanmugam, and Caroline Uhler, “Identifiability Guarantees for Causal Disentanglement from Soft Interventions,” Proceedings of the 37th International Conference on Neural Information Processing Systems, December 2023.
- Xun Zheng, Bryon Aragam, Pradeep Ravikumar, and Eric P. Xing, “DAGs with NO TEARS: Continuous Optimization for Structure Learning,” Neural Information Processing Systems, November 2018.
Your Privacy
We want to demonstrate our commitment to your privacy. Please review Chicago Booth's privacy notice, which provides information explaining how and why we collect particular information when you visit our website.